\ Internal Developer Platforms are the hottest investment in DevOps right now. They're also failing silently at most organisations, not because the engineering is bad, but because the product thinking is absent. Here's what's actually going wrong, and how to fix it before you torch another budget cycle.
The Number That Should Terrify Every Platform Team
Gartner projects that by the end of 2026, 80% of large software engineering organisations will have a dedicated platform team, up from roughly 45% just three years ago. Billions of dollars in engineering headcount, tooling licenses, and infrastructure are flowing into Internal Developer Platforms (IDPs) right now.
And then this, buried in a Medium post that made the rounds in April 2026: an engineering org spends $4.2 million on an IDP initiative, Backstage portal, Kubernetes golden paths, the works, runs their first developer satisfaction survey, and discovers that 64% of engineers are still side-stepping the entire platform to deploy with a raw kubectl run command.
I want to sit with that number for a moment. Sixty-four percent. After 18 months and four million dollars.
This is not an isolated story. It's the pattern. And as someone who has spent the last few years architecting cloud platforms and building tooling that engineers actually use, I can tell you the problem is rarely the technology.
What Platform Engineering Actually Promises
Before I go further, let's be precise about what we're talking about. Platform engineering isn't just DevOps with a fancier name. It's a specific organisational model built on one core idea: treat your internal infrastructure as a product, with your development teams as customers.
That means:
- A self-service portal (often Backstage) where engineers can provision environments, spin up services, and access templates without opening a ticket
- Golden paths, opinionated, pre-approved patterns for how services should be built and deployed
- Automated compliance, security scanning, and cost guardrails baked in by default
- A platform team that owns and maintains all of this as a long-lived product capability
The promise is compelling. Teams with mature IDPs report dramatic reductions in provisioning lead times, better security posture, and significantly lower cognitive load on individual engineers. The 2025 DORA Report found that 90% of organisations have now adopted at least one internal platform, and there is a direct correlation between high-quality internal platforms and an organisation's ability to unlock value from AI. Platform engineering is the mechanism that makes consistent, high-quality delivery possible at scale.
So why is it failing in practice?
The Three Failure Modes Nobody Talks About
Failure Mode 1: The Platform Was Built for the Builder, Not the User
Here's the uncomfortable truth about most IDP implementations: they are built by people who love infrastructure, for people who would rather not think about it.
Platform engineers are, by selection, people who find the complexity of Kubernetes, Terraform, and service mesh configuration genuinely interesting. That's the job. But the developers using the platform are trying to ship features. They don't care how elegant your Helm chart templating is. They care whether they can go from idea to running service without spending three hours reading internal documentation.
The golden path that isn't actually the path of least resistance will be abandoned. Every time.
I've seen this play out repeatedly: a platform team builds a beautifully architected service template. It enforces the right security policies, the right observability hooks, the right resource limits. It takes 45 minutes to get a new service running end-to-end because there are seven configuration steps and two approvals. The engineer who needs a service now runs
kubectl run. It takes four minutes.
You have not failed because your platform is technically inferior. You have failed because you optimised for correctness over experience.
Failure Mode 2: Cost Visibility Was an Afterthought
This is a recurring issue across organisations.
Platform teams invest heavily in deployment pipelines, secret management, and service catalogues. Spend visibility usually gets bolted on at the end, or delegated entirely to a FinOps team that publishes a monthly report nobody reads.
The result is predictable: engineers provision environments with no real feedback loop on what those environments cost. A perfectly reasonable-looking ephemeral test environment gets created for a load test, forgotten, and quietly accumulates significant monthly spend. Multiply that across dozens of teams, and you have a cost problem that no amount of Kubernetes right-sizing will fix.
Cloud and AI costs are no longer predictable or linear. Ephemeral environments, GPU workloads, managed services, and AI inference can shift spend dramatically in days, not months. Cost guardrails need to be embedded inside the platform, not positioned adjacent to it.
The platforms that surface cost impact at the point of provisioning, “this environment will cost approximately £180/month, confirm?”, change engineer behaviour in a way that delayed reporting never will. Feedback loops only work when they are immediate and contextual.
Failure Mode 3: The Platform Doesn't Compose With How Engineers Actually Work
Most IDPs are designed around a portal interaction model: engineer logs into Backstage, clicks through a wizard, provisions a resource. Clean, auditable, governed.
Most engineers don't work that way. They work in their IDE, their terminal, and their Slack. They live in GitHub. They want to type a command or trigger an action from where they already are, not switch context to a separate web interface.
64% of engineers are still side-stepping everything built to deploy with a raw kubectl run command. That's not laziness. That's engineers rationally optimising for the fastest path to their actual job. If your platform doesn't meet them where they are, they will route around it.
The platforms that have the highest adoption are the ones that are invisible at low-friction moments and visible at high risk moments. You don't need a portal for someone to deploy a staging environment, you need a CLI, a GitHub Actions workflow, or a Slack slash command. You do need a visible, enforced gate when someone is trying to deploy untested code to production.
What the Platforms That Actually Work Have in Common
I've worked with and studied enough platform implementations at this point to see the pattern in what succeeds. It comes down to four things:
Developer Experience is a First-Class Metric
The teams that get this right measure platform adoption the same way a product team measures user retention. They track not just "is the platform being used?" but "at which points in the workflow do engineers abandon it, and why?"
They run office hours. They embed platform engineers into product squads for a sprint at a time to observe friction firsthand. They treat a low NPS from a developer team as a critical bug, not a culture problem. The 2024 DORA Report confirmed that utilising an internal developer platform improves individual productivity, team performance, and overall organisational performance, but only when developer experience is treated as a core outcome.
The Golden Path is Actually Golden
A golden path that requires three approvals and an internal ticket is not a path, it's a bureaucracy with a friendly name. The best implementations I've seen have genuinely collapsed provisioning time. New service, correctly configured, observable, secure, deployed to a non-production environment: under ten minutes, no tickets, no approvals for standard configurations.
This means the platform team has done the hard work of pre-negotiating the security and compliance requirements with the relevant stakeholders and encoding them into the template itself. The approval happened once, at template design time, not every time an engineer uses it.
Cost Intelligence is Embedded, Not Adjacent
Infracost integration in every Terraform PR. Environment cost estimates at provisioning time. Automatic TTL warnings on ephemeral environments ("this environment has been running for 14 days with no activity, shut it down?"). Budget threshold alerts that go to the team, not just to a central FinOps function.
This is the shift from cost reporting to cost awareness. The goal isn't to stop engineers spending money, it's to make them spend it consciously.
The Platform Grows in the Terminal, Not Just the Portal
The highest-adoption IDPs I've encountered all have a strong CLI story. platform create service my-api --template=python-fastapi should just work. platform env list --cost should show you running environments and their estimated monthly spend. platform deploy --env=staging should be a single command that handles everything the Backstage wizard does, without leaving the terminal.
This isn't about replacing the portal. It's about making the platform usable in the contexts where engineers actually spend their time.
The Architectural Pattern: Platform as a Product
Let me make this concrete with a reference architecture that addresses all three failure modes.
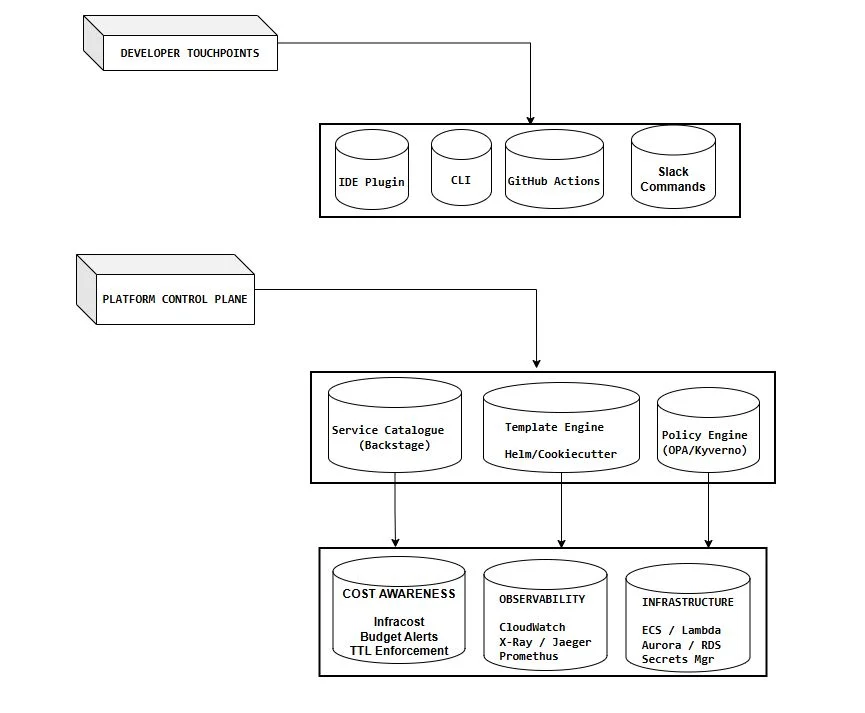
The key principle: every developer touchpoint talks to the same control plane. Whether an engineer provisions a service via the Backstage portal, a CLI command, a GitHub Actions workflow, or a Slack slash command, they go through the same policy engine, the same cost checks, the same observability hooks. The experience differs; the governance doesn't.
This is how you get high adoption and high compliance. Not by forcing engineers into a single interface, but by making every interface they prefer equally safe.
The Multi-Cloud Wrinkle
Everything described above becomes significantly more complex the moment workloads span AWS, Azure, and GCP, which, by 2026, is increasingly the default rather than the exception. According to the Flexera State of the Cloud Report, a majority of organisations now operate in hybrid or multi-cloud environments.
Multi-cloud platform engineering introduces a specific failure mode: the cost visibility gap. A platform team may have strong visibility into workloads running in AWS, reasonable insight into Azure, and limited real-time visibility into GCP, especially where teams adopt specialised services like AI platforms independently.
The result is fragmented cost awareness. Different teams operate across different providers, each with separate billing models, tooling, and reporting layers. Without unified visibility, cost governance becomes reactive rather than continuous.
The platforms that address this effectively are those that integrate multi-cloud cost intelligence directly into the developer workflow. When engineers can understand cost impact across providers at the point of decision, cost management shifts from a periodic finance exercise to an everyday engineering practice.
The IDP that embeds multi-cloud cost visibility, not just single-cloud reporting, is the one that meaningfully changes behaviour in teams running the most expensive workloads.
Practical Recommendations: Where to Start
If you're building or rescuing an IDP, here's the sequence I'd recommend:
First: measure adoption, not deployment. Before you add a single new feature, instrument what's actually being used. Which golden paths have been run more than once? Which services provisioned through the platform are still running six months later versus which ones were created and then bypassed? This data will tell you where the real friction is.
Second: fix the provisioning time. Whatever your current end-to-end time is for a new service from zero to deployed in non-prod, cut it in half. This is your most important adoption lever. Everything else is noise if the fundamental loop is slow.
Third: build the CLI. Even a thin wrapper that calls your existing APIs. Ship it to engineers and watch how they use it. The commands they reach for most naturally are the ones your portal needs to optimise around.
Fourth: embed cost in the provisioning flow. Not a link to a cost dashboard. An inline estimate, at the moment of provisioning, that requires acknowledgement. This single change will have more impact on your cloud bill than any rightsizing exercise.
Fifth: establish a platform NPS cadence. Quarterly is minimum. Monthly is better. Treat a score below 7 from any team as an incident. Assign it. Investigate it. Fix it.
The Real Question for 2026
For engineering leaders, the question in 2026 is no longer whether internal platforms will exist, Gartner's forecast of 80% adoption by year-end makes that inevitable. The question is whether they will be intentional or accidental. The difference shows up in adoption, resilience, and the ability to evolve without constant rework.
That framing is exactly right, but I'd push it one step further: the question isn't just intentional versus accidental. It's product-led versus infrastructure-led.
Platforms built by people who love infrastructure, primarily optimised for technical correctness, will have 64% bypass rates. Platforms built by people who understand that their users are developers trying to ship fast, optimised for experience first and governance second (while still enforcing governance), will have the opposite problem: engineers will want to use them even for things that don't strictly require it.
That's the goal. Build the platform so good that bypassing it feels like leaving performance on the table.
Final Thought
Four million dollars and 18 months for a platform 64% of engineers avoid. I don't tell that story to mock the team that built it,
I tell it because it could be any of us.
The infrastructure was probably excellent. The golden paths were probably technically sound. The Backstage portal was probably beautiful. And none of it mattered because the product thinking wasn't there from the start.
Platform engineering is one of the most exciting disciplines in our field right now. It's also the one where the gap between what we measure (did we deploy a platform?) and what we should measure (are engineers using it by choice?) is widest.
Close that gap. Everything else follows.
References
Gartner. Top Strategic Technology Trends: Platform Engineering. Gartner, Inc. https://www.gartner.com/en/infrastructure-and-it-operations-leaders/topics/platform-engineering
Shah, Neel. The Hidden Adoption Crisis in Platform Engineering and How to Actually Fix It. Medium / Devops & AI Hub, April 2026. https://medium.com/devops-ai-decoded/the-hidden-adoption-crisis-in-platform-engineering-and-how-to-actually-fix-it-cd3afec3042e
Google Cloud / DORA. 2025 DORA Report: State of AI-Assisted Software Development. September 2025. https://cloud.google.com/blog/products/ai-machine-learning/announcing-the-2025-dora-report
Flexera. 2026 State of the Cloud Report. April 2026. https://info.flexera.com/CM-REPORT-State-of-the-Cloud
DORA. Accelerate State of DevOps Report 2024. https://dora.dev/research/2024/dora-report/
\ \ \ \

